

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 92521大模型×文本水印:清华、港
- 91412一文读懂如何基于 GenA
- 910832024 年,3 项技术将
- 90764AI在工业物联网(IIoT
- 90705利用人工智能增强网络安全防
- 90696GPT-4准确率最高飙升6
- 90657人工智能和机器学习在物联网
- 90488一句话让小姐姐为我换了N套
- 90419AI时代来了,专业摄影师会
- 9041102024年人工智能与数字孪
推荐阅读
- 01-241技术趋势:2024年的热点是什么
- 01-252网络安全在自动驾驶汽车中的作用
- 01-253OpenAI创始人想打造全球芯片
- 01-264强化学习和世界模型中的因果推断
- 01-265Mamba论文为什么没被ICLR
- 01-296让知识图谱成为大模型的伴侣
- 01-297从20亿数据中学习物理世界,基于
- 01-298谷歌云与Hugging Face
- 01-299人工智能和机器学习在物联网中的作
- 01-2910无需人工标注!LLM加持文本嵌入
Tokenization?指南:字节对编码,WordPiece等方法Python代码详解
在2022年11月OpenAI的ChatGPT发布之后,大型语言模型(llm)变得非常受欢迎。从那时起,这些语言模型的使用得到了爆炸式的发展,这在一定程度上得益于HuggingFace的Transformer库和PyTorch等库。
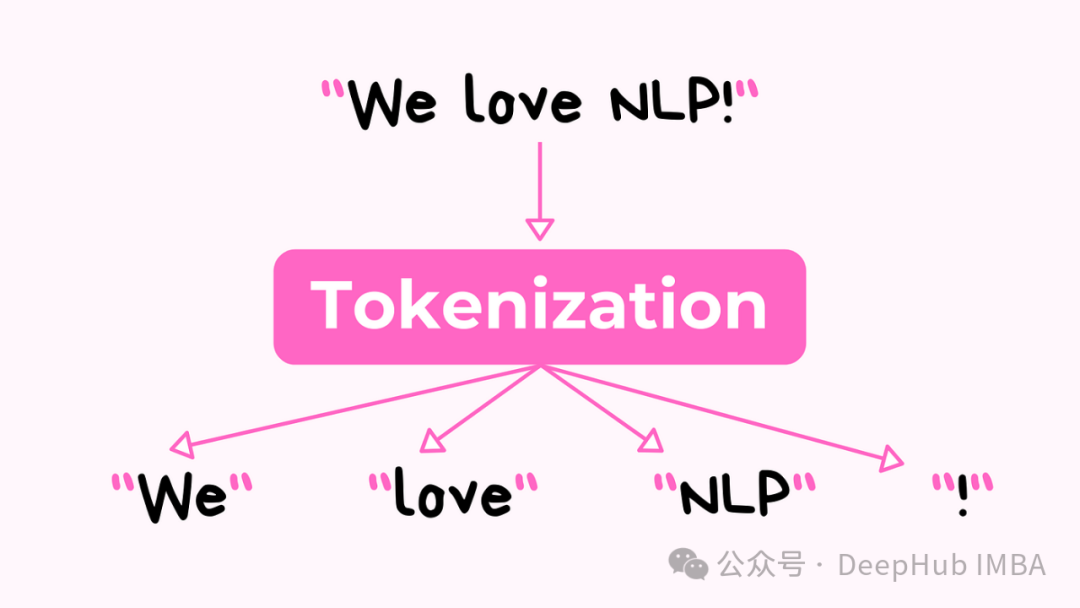
计算机要处理语言,首先需要将文本转换成数字形式。这个过程由一个称为标记化 Tokenization。
标记化分为2个过程:
1、将输入文本划分为token
标记器首先获取文本并将其分成更小的部分,可以是单词、单词的部分或单个字符。这些较小的文本片段被称为标记。Stanford NLP Group[2]将标记更严格地定义为:
在某些特定的文档中,作为一个有用的语义处理单元组合在一起的字符序列实例。
2、为每个标记分配一个ID
标记器将文本划分为标记后,可以为每个标记分配一个称为标记ID的整数。例如,单词cat被赋值为15,因此输入文本中的每个cat标记都用数字15表示。用数字表示替换文本标记的过程称为编码。类似地将已编码的记号转换回文本的过程称为解码。
使用单个数字表示记号有其缺点,因此要进一步处理这些编码以创建词嵌入,这个不在本文的范围内,我们后面介绍。
标记方法
将文本划分为标记的主要方法有三种:
1、基于单词:
基于单词的标记化是三种标记化方法中最简单的一种。标记器将通过拆分每个空格字符(有时称为“基于空白的标记化”)或通过类似的规则集(如基于标点的标记化)将句子分成单词[12]。
例如,这个句子:
Cats are great, but dogs are better!关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP